








In cooperative multi-agent reinforcement learning (MARL), due to its on-policy nature, policy gradient (PG) methods are typically believed to be less sample efficient than value decomposition (VD) methods, which are off-policy. However, some recent empirical studies demonstrate that with proper input representation and hyper-parameter tuning, multi-agent PG can achieve surprisingly strong performance compared to off-policy VD methods.
Why could PG methods work so well? In this post, we will present concrete analysis to show that in certain scenarios, e.g., environments with a highly multi-modal reward landscape, VD can be problematic and lead to undesired outcomes. By contrast, PG methods with individual policies can converge to an optimal policy in these cases. In addition, PG methods with auto-regressive (AR) policies can learn multi-modal policies.
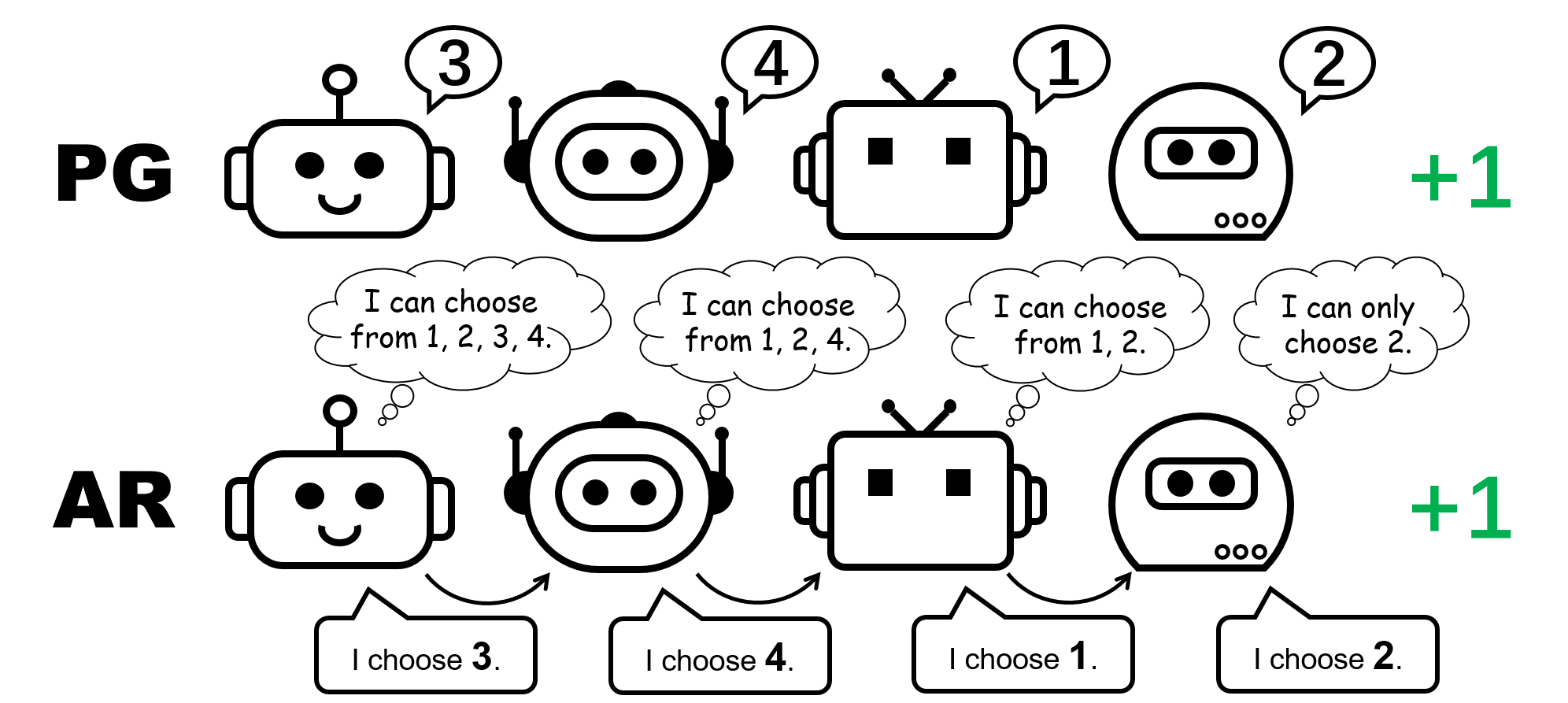
Figure 1: different policy representation for the 4-player permutation game.
