Please, feed your data to the machines.
Artificial intelligence is taking the demand for data to a new level. 📈
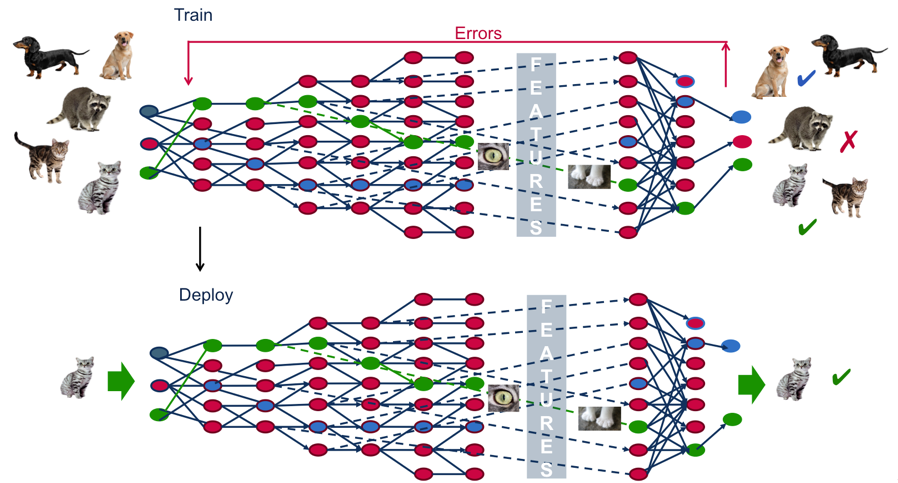
Let’s say you have access to 5,000 X-ray images of patients who were correctly diagnosed with a particular type of cancer — Type A.
Today, it is surprisingly easy to use this data to train a bot to detect this cancer in new patients.
To build this bot, you’d build an image classifier powered by a neural net and the 5,000 X-ray images would be your training data set.
You’d add another 5,000 X-rays of patients without cancer so the classifier has examples of both healthy and affected X-rays.
In essence, this image classifier bot would look for common patterns at pixel level using image gradients and correlate that pattern to Type-A cancer using a widely used machine learning algorithm called back-propagation.
Note that YOU don’t have to specify the patterns at the pixel level to the bot for it to detect the cancer. That would be a highly inefficient process and possibly inaccurate as well.
Instead, in our deep learning model, the bot looks for the patterns itself. It painstakingly evaluates small grids of pixels of an image with the cancer and compares it to the corresponding grid in ALL the other images to find the patterns that exist. For further reading, you can check out concepts like kernel convolutions or how bots are detecting various object in Kaggle competitions.
If you want to dive deeper into the tech, you can read my essay “Learning at Scale & The End of ‘If-Then’ Logic”.
The point is, using currently available open-source/SaaS deep learning platforms, a bit of motivation and access to the right data set, one could set this bot up in no time.
Once trained, if you input a new patient’s X-ray, the classifier would be able to say things like “There’s a 98% chance that this is a Type A Cancer”.
If you’ve been through a cancer diagnosis process of a loved one, you know how important it is to be certain. That’s why people get the second, the third and the fourth opinion from different doctors.
Using this bot, every patient can be more confident about a diagnosis, a lot faster.
The best part is that if you continue to add more X-ray images of correctly diagnosed Type A cancer, the bot will continue to get better at detecting it.
As machine learning techniques become more mainstream, a lot more value will be placed on data because machines can learn from it to do our jobs better than us.

This above use-case isn’t science fiction.
At John Radcliffe Hospital, a team of researchers from Oxford University are using electrocardiogram images (Eco test) of the heart to detect heart diseases. The system is called Ultromics and it consistently performs better than human cardiologists. The team has access to Oxford University’s heart imaging database and they are training their machine learning algorithms with these images to detect various heart diseases.
Google’s DeepMind is using a similar system to train an AI to detect eye disease by looking at thousands of retina scans at London’s Moorfields Eye Hospital.
In a double blind study, IBM Watson for Oncology’s breast cancer treatment recommendations was 90% concordance with the recommendation of a tumor board consisting of multi-disciplinary doctors and practitioners. Here, the training data comes from medical records of past patients, medical journal and books.
Needless to say, AI/ML use-cases are not limited to healthcare but they show us how valuable data is to solve real problems.
Most organizations/businesses/governments are sitting on top of literal goldmines of data that could be made into powerful AI products.
Unfortunately, not enough is being done. Not fast enough.
Data is a source of great power. And with great power comes great responsibility.*
So if you’ve got access to valuable data, you better be building something useful with it.